An MSR, or Model-Specific Register is a natural-width (i.e the size of a pointer) buffer that contains data which either affects processor behaviour or is used to store processor-specific data which is deemed to not go into a CPUID leaf. Trying to interact with an invalid MSR index will result in a General-Protection Fault, or a #GP(0) (the (0) meaning an error code of 0). MSRs are virtualized or emulated by the Virtual Machine Monitor. Generally speaking, an MSR read or write will trap into the VMM/hypervisor so it can give the correct response (newer processors contain features such as MSR bitmaps for Intel's Virtual Machine eXtensions which specify the MSRs that do this). Therefore, if a hypervisor decides to not implement the proper response for an MSR interaction, it can be used as a way to detect it. So, back to invalid MSR indices. Intel defines a range of MSRs which, unless subverted by a hypervisor, will always be invalid, no matter what CPU you're using (provided it's Intel). These are MSRs 40000000h - 400000FFh. As said before, reading or writing to these MSRs will always cause a #GP(0). Unless, of course, you're running under VMware. One day, while messing around with my hypervisor inside of VMware and reading random MSRs, well, let the image speak for itself: I was able to read a normally invalid MSR! This means that one could detect VMware by simply doing:
#define HV_SYNTHETIC_MSR_RANGE_START 0x40000000
__try
{
__readmsr( HV_SYNTHETIC_MSR_RANGE_START );
}
__except(EXCEPTION_EXECUTE_HANDLER)
{
return FALSE;
}
return TRUE;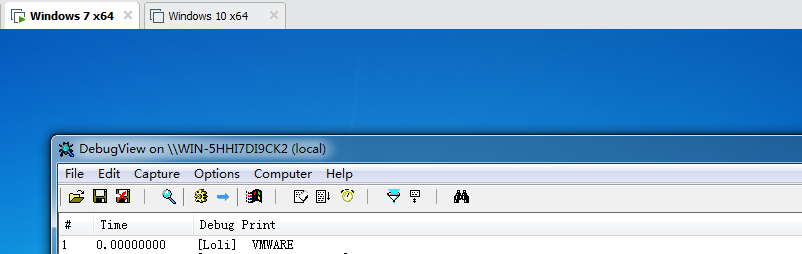
simply edit your .vmx file. Add the following line to file:
hypervisor.cpuid.v0 = "FALSE"
——----------------------------------------------------------------------------------------------------------------------
LBR Stack Checks
In addition to the above check, an anti-cheat could implement a detection based on the usage of saved/loaded LBR information between VMX transitions. Since many open-source projects don’t handle store/load of LBR information appropriately an anti-cheat could force a VM-exit through use of an unconditionally exiting instruction like . After the execution, they would need to check the last branch taken from the LBR stack after resuming guest operation. If the target address doesn’t match the expected value it would mean that some introspective engine is present.
CPUID// Save current LBR top of stack
auto last_branch_taken_pre = __read_lbr_tos();
// Force VM-exit with CPUID
__cpuid(0, ®s);
// Save post VM-exit LBR top of stack
auto last_branch_taken_post = __read_lbr_tos();
// Compare last branch taken
if(last_branch_taken_pre != last_branch_taken_post)
return TRUE;
This would be quite effective at catching hypervisors leveraging LBR but not properly handling the storage of LBR information. The LBR stack consists of pairs of MSRs that store the last branch source and target addresses. There are 8 MSRs associated with these listed below.
// Last Branch Source Addresses
MSR_LASTBRANCH_0_FROM_IP
MSR_LASTBRANCH_N-1_FROM_IP
// Last Branch Target Addresses
MSR_LASTBRANCH_0_TO_IP
MSR_LASTBRANCH_N-1_TO_IP
And the which is the MSR containing the LBR top of stack pointer. With this and knowledge of the VM-exit/VM-entry MSR-store areas documented in the Intel SDM we can save the LBR stack and top of stack when a VM-exit is encountered, then restore them on VM-entry to the guest. The LBR stack size can be determined from this table:
MSR_LASTBRANCH_TOSThe hypervisor would need to have an area allocated where you would then store the values of the LBR stack information, and then write the load/store count and address to the respective VMCS fields: and . This will successfully prevent LBR stack checks from catching the VMM.
VMCS_VM_EXIT_MSR_(LOAD/STORE)_COUNTVMCS_VM_EXIT_MSR_(LOAD/STORE)_ADDRESSINVD/WBINVD
This method is used to determine if the hypervisor emulates the INVD instruction properly. As is expected, many public platforms do not emulate the instruction appropriately leaving a detection vector wide open. This method was supplied by a member of ours, drew, who uses it and corroborates its effectiveness.
pushfq
cli
push 1 ; Set cache data
wbinvd ; Flush writeback data set from previous instruction to system memory.
mov byte ptr [rsp], 0 ; Set memory to 0. This is in WB memory so it will not be in system memory.
invd ; Flush the caches but do not write back to system memory. Real hardware will result in loss of previous operation.
pop rax ; Proper system behaviour will have AL = 1; Hypervisor/emulator that uses WBINVD or does nothing will have AL = 0.
popfq
ret
The subtle behaviors of a real system should be emulated properly to avoid this type of detection. It’s present on a handful of open-source hypervisor platforms. As an exercise to the reader, try to determine how to mitigate this side-channel.
There are many other cache side-channels; the most common is gathering statistics on cache misses and locating conflicting cache sets. These can be hit or miss depending on implementation and require lots of testing prior to implementation to ensure very few, if any, false positives. These types of solutions require making sure that the prefetcher is unable to determine cache usage by randomizing cache set accesses and ensuring that new reads from a cache set are correct in terms of how many lines are read, whether the valid cache lines were probed properly, and so on. It’s a very involved process, so we didn’t plan on including the implementation of such a check in this article.
The above method is example is enough to be validated, and we encourage you to validate it as well! Be aware that this can cause if SGX is used.
#GP(0)RDTSC/CPUID/RDTSC
If you’ve done performance profiling, or worked on sandbox detection for anti-malware (or more questionable purposes), you’ve likely used or encountered this sort of timing check. There’s plenty of literature covering the details of this attack, and in most cases it’s relatively effective. However, hypervisor developers are becoming more clever and have devised methods of reducing the time discrepancies to a very low margin.
This timing attack used to determine if a system is virtualized or not is common in anti-cheats as a baseline detection vector. It’s also used by malware to determine if it is sandboxed. In terms of effectiveness, we’d say it’s very effective. The solution, while somewhat confusing, passes the pafish checks and anti-cheat checks. We won’t be divulging any code, but let’s briefly go over the logic.
We know that timing attacks query the timestamp counter twice, either by direct use of the MSR or the intrinsic . Typically there will be instructions in between. Those instructions will cause VM-exits, typically, so the idea is to emulate the cycle count yourself - adding to an emulated cycle counter. You could use a disassembler, add an average, or devise a method that’s much more accurate. Trace from the first instruction to the second, add an average cycle count to the emulated counter. No TSC offsetting, or other feature is utilized - though you can, for example, take advantage of the MTF. You will also need to determine an average number of cycles the VM transitions take and subtract that from the emulated counter. The typical average is between 1.2k - 2k cycles on modern processors.
IA32_TIMESTAMP_COUNTER__rdtscrdtscSuccessfully implementing the solution, while not perfect, yields better results than the majority of tested solutions presented in literature and passes the virtualization checks devised. It’s important when attempting to implement the solution to not get bogged down with unnecessary details like SMIs, or how to synchronize (you do have to have a counter that is invariant across logical processors though). Keep it simple, silly.
IET Divergence
As an opposition to the standard timing attack we offer a more novel approach that doesn’t rely on the timestamp counter and requires much more effort to spoof. It has been briefly mentioned in a post here, and we decided to go into a little more detail.
IET divergence is the measurement and comparison of instruction execution time (IET) using two different instructions. Similar to the combination, IET divergence test uses a counter to profile two instructions, calculate the average execution time, and then compare the two instructions’ results. This detection method uses the actual performance counter accessed through IA32_APERF MSR instead of the timestamp counter. As discussed before the TSC can be emulated with relative ease, and poses a threat to standard detection methods. Spoofing the APERF counter is much more difficult and isn’t as simple as forcing a VM-exit on the APERF MSR and performing similar operations as the TSC emulation.
rdtsc;cpuid;rdtscThe test works like this:
- Disable interrupts.
- Setup registers for profiling loop.
- Capture a starting clock count for an instruction ().cpuid
- Execute with the same leaf every time, and capture end clock count.
- Calculate the difference in clock count for that loop.
- Store result in CPUID_IET array.
- Repeat for second candidate instruction.
- Repeat loop N times for a more refined timing profile.
Choosing the instructions is the most difficult part to this check as you will need to use an unconditionally exiting instruction to ensure that if a VMM is present the processor traps into it. The ideal candidate would be , but the second instruction must be chosen with care. It’s average IET must be longer than on real hardware, otherwise the check is pointless. The whole point is to compare the execution times of one instruction to an instruction that takes longer on real systems, because in a virtual environment will consume a lot of cycles before completing. The candidate instruction should take longer than the profiling target, not be a an instruction that could be trapped by the hypervisor, and can be setup relatively easily.
cpuidcpuidcpuidThe IET divergence test is used by some anti-cheats as a counter to the more advanced hypervisors used for cheating. A sample implementation is shown below.
cli
xor r8d, r8d
mov ecx, IA32_APERF_MSR
rdmsr
shl rdx, 20h
or rax, rdx
mov r9, rax
lea rsi, [rsp+20h]
xor eax, eax
cpuid
mov [rsi], eax
mov [rsi+4], ebx
mov [rsi+8], ecx
mov [rsi+0Ch], edx
mov ecx, IA32_APERF_MSR
rdmsr
shl rdx, 20h
or rax, rdx
mov rdx, [rsp+30h]
sub rax, r9
mov [rdx+r8*8], rax
;
; TODO:
; Capture comparable instruction IET.
; Store result.
; Loop. Break at end.
; Enable interrupts.
; End profile.
;
This is an incomplete implementation and the steps would need to be repeated for the second instruction that executes longer than . The choosing of the second instruction is important to getting clear results. That being said, the effectiveness of this detection method is quite remarkable as it will catch even the most well hardened hypervisors. If you have a platform and are interested in researching the products that use this we encourage you to exit on APERF accesses and give some of the private anti-cheats a look.
cpuidCRn Mask & VMX Availability
For each position corresponding to a bit clear in the CRx guest/host mask, the destination operand is loaded with the value of the corresponding bit in CRx. For each position corresponding to a bit set in the CRx guest/host mask, the destination operand is loaded with the value of the corresponding bit in the CRx read shadow. Thus, if every bit is cleared in the CRx guest/host mask, MOV from CRx reads normally from CRx; if every bit is set in the CRx guest/host mask, MOV from CRx returns the value of the CRx read shadow.
Based on this, hypervisors may set the bit to 0 in the read shadow while having the guest/host mask for set that bit to 1. This would mean that if a guest were to read the value of that bit they would get 0. However, the bug that can be exploited on some platforms is that they signal being disabled, but VMX instructions still execute. That’s not possible, and is a blatant indication that virtualization is being used.
CR4.VMXECR4CR4VMXEThe fix for this would be to inject an undefined opcode exception () into the guest on execution of a VMX instruction if you intend to mask off the bit. Some public platforms inject to the guest for execution of VMX instructions as opposed to which is the proper exception. This is also indicative of presence.
#UDVMXE#GP(0)#UDCPUID Leaf Comparisons
A quick method similar to the reserved MSR address ranges is the check reserved responses against what their values would normally be. As an example, the leaf is a CPUID leaf marked reserved by the architecture and is most commonly used for reporting capabilities of a VMM. There are two options which is to check against an invalid leaf or a leaf that returns the same data. Two examples are below.
CPUID40000000hThis first example displays using an invalid CPUID leaf to determine if the system is virtualized.
UINT64 UmpIsSystemVirtualized(void)
{
unsigned int invalid_leaf = 0x13371337;
unsigned int valid_leaf = 0x40000000;
struct _HV_DETAILS
{
unsigned int Data[4];
};
_HV_DETAILS InvalidLeafResponse = { 0 };
_HV_DETAILS ValidLeafResponse = { 0 };
__cpuid( &InvalidLeafResponse, invalid_leaf );
__cpuid( &ValidLeafResponse, valid_leaf );
if( ( InvalidLeafResponse.Data[ 0 ] != ValidLeafResponse.Data[ 0 ] ) ||
( InvalidLeafResponse.Data[ 1 ] != ValidLeafResponse.Data[ 1 ] ) ||
( InvalidLeafResponse.Data[ 2 ] != ValidLeafResponse.Data[ 2 ] ) ||
( InvalidLeafResponse.Data[ 3 ] != ValidLeafResponse.Data[ 3 ] ) )
return STATUS_HV_DETECTED;
return STATUS_HV_NOT_PRESENT;
}
This second example uses the highest low function leaf to compare data to what would be given on a real system.
UINT64 UmpIsSystemVirtualized2(void)
{
cpuid_buffer_t regs;
__cpuid((int32_t*)®s, 0x40000000);
cpuid_buffer_t reserved_regs;
__cpuid((int32_t*)&reserved_regs, 0);
__cpuid((int32_t*)&reserved_regs, reserved_regs.eax);
if (reserved_regs.eax != regs.eax ||
reserved_regs.ebx != regs.ebx ||
reserved_regs.ecx != regs.ecx ||
reserved_regs.edx != regs.edx)
return STATUS_HV_DETECTED;
return STATUS_HV_NOT_PRESENT;
}